
In the computer and online world, something called the ASCII code is essential. You might have heard about this code or table thing before. But right now, we’re going to look at what ASCII is and see how it has changed from the past to now.
First of all, ASCII stands for the American Standard Code for Information Interchange. It’s a way of turning letters and symbols into numbers. They made it in the 1960s. Before that, computers used different ways to understand things. However, when ASCII came along, it made it simpler for devices to share information.
What is the Definition and Importance of ASCII?
ASCII is a way of coding characters in computers. They used it many times to write on phones and computers. The cool thing is it helps show text in the same way on all kinds of devices.
If you work with computers or digital devices, you should know about ASCII. Nowadays, we have lots of modern character systems. However, with ASCII, it would be easier for devices to talk to each other.
So, understanding this is helpful for both people who build things on computers and those who write code. Basically, it helps them make their software work better and faster.
We need to know that ASCII is the foundation for the super-advanced character codes we have now.
ASCII History and Development
Back in the 1870s, a French developer named Émile Baudot made a binary code for telegraphs. This code was five bits and sent messages over the telegraph. But it couldn’t handle all the letters of the Latin alphabet. So this led to the creation of the ASCII code.
If we look at its history, we will see that Bob Bemer and some other computer scientists worked together on a project. Their goal was to make text look the same on various computer systems and devices. After their research, they came up with the ASCII system in the 1960s. Some people also call it Basic ASCII.
ASCII Types
In the field of programming and software, it is essential to know its types. Even with lots of programming languages, it’s necessary to understand the kinds of characters they work with.
Let’s say you’re making software with characters that aren’t in English. In that situation, you should use Extended ASCII or Unicode. Or, you could go for newer types like UTF-8.
To sum it up, we divide this group into two main parts, 7-bit and 8-bit, like this:
1. ASCII-7 (Basic)
In 1963, the American Standards Association (ASA) put out the first official version of it called ASCII-63. It had 128 characters in a 7-bit set. At first, it only had English letters in both big and small sizes, and it also had numbers from 0 to 9.
Of course, it didn’t stick to just English. Over time, they kept working on it and made an 8-bit version called ASCII-7. So, this new version had more information than the old one, so it could handle more languages.
As technology got better, computers had to do more things. So, they needed more ways to understand characters. Thus, they worked on the 128-character setup and added more characters and symbols. In other words, they called this Extended ASCII, which is more advanced than the regular version.
2. ASCII-8 (Extended ASCII)
To meet the growing needs, IBM made Extended ASCII. It had more symbols, characters, and even pictures than the first one. This second type had 256 characters. It also led to something called ASCII Art.
IBM wanted to use this 8-bit version in their first computers in 1981. Additionally, it had characters from other languages too. But since this version didn’t become a standard, it caused issues. In short, different companies used different ways of coding, making it hard for systems to work together.
Next Character Encoding Types
In the late 1980s, they tried to make a code that works for everyone. This led to the creation of Unicode character encoding. So, the old systems still used the first one, but new stuff started using Unicode.
The first version of Unicode, called Unicode 1.0, had 7,096 characters in 1991. Fast forward to 2023, and version 15.1 has a whopping 149,813 characters! Its goal remains the same: to have one way of writing that works for every language and writing system around the world. In short, they want lots of people to use it.
In simple terms, Unicode came from the original and extended ASCII code. It works with both and has characters that the others don’t. Plus, it uses 16-bit and 32-bit values to show every bit of text or symbol.
After Unicode, there’s another type called UTF-8. It represents Unicode data in a small way, using one to four bytes for each character. Simply put, UTF-8 works with Standard or Basic. Thus, this means it can handle data from the original, extended, and Unicode sets.
Even today, especially in PC software development, the ASCII code is still necessary. Lots of programming languages use it to show text. Even though new versions have come out, it’s still the basic foundation. And some older things, like email or moving files around, still use it.
What is an ASCII Table?
If you’re interested in PC history, you might have come across a character set table. So, what exactly is the ASCII code table, and why is it important?
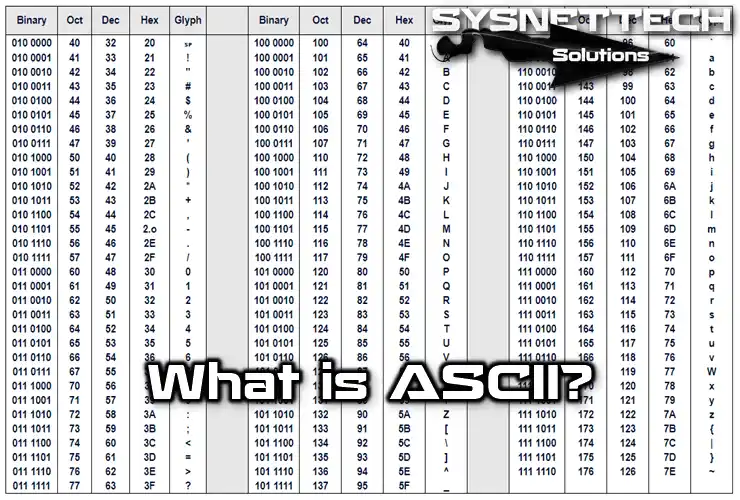
The character set table is like a list that gives numbers to each letter, number, or symbol. It’s a way of giving each of them a unique code. This table is all organized and standard. However, it can have either 128 or 256 characters because 7-bit and 8-bit types handle different numbers of characters.
Now, let’s quickly talk about the 7-bit character codes table:
- Letters
- Uppercase letters (A-Z) use codes from 65 to 90.
- Lowercase letters (a-z) use codes from 97 to 122.
- Digits
- Numerical digits (0-9) are in the range from 48 to 57.
- Symbols
- Different symbols and punctuation marks are in other spots on the table.
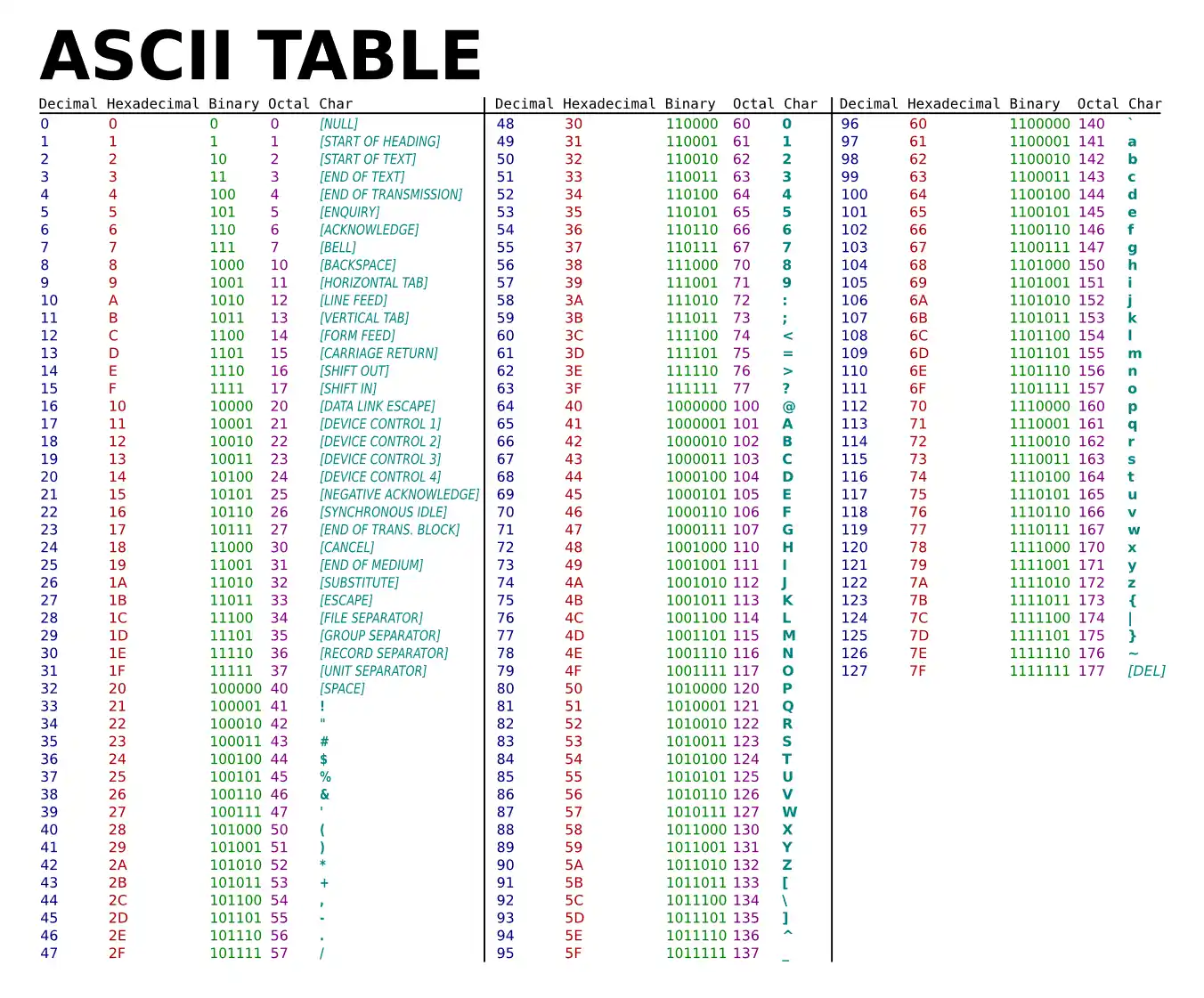
The ASCII table matters because it helps computers understand and show text. For instance, it says that the exclamation mark (!) is code 33, and the dollar sign ($) is code 36. So, when you hit the “A” key, your computer turns it into code 65 and saves it in its memory.
Control Characters in the Table
Also, in the character set table, there are special codes for control characters. For instance, when you hit a key to make the cursor go back to the start of a line, your PC turns it into code 13 (CR – Carriage Return).
The numbers in the table help you handle data. Basically, you can decide how a character looks. It’s not just for making text look nice; you can also use it to manage tasks in data communication.
For instance, the most commonly used control sets are:
- Start of Header (SOH – Code 1):
- This character doesn’t match a specific key on the keyboard. So, it’s a unique control code used in things like talking between devices or programming.
- Carriage Return (CR – Code 13):
- It usually corresponds to the “Enter” key on the keyboard. This key completes a text line and moves to the following line.
- Line Feed (LF – Code 10):
- Likewise, it doesn’t have its key, but it teams up with the “Enter” key. It shows the end of a text line and lets you go to the following line.
- Acknowledge (ACK – Code 6):
- It doesn’t match a key directly. Still, it’s a unique control character used in sending data between devices.
- End of Text (ETX – Code 3):
- This character usually doesn’t match a specific key on the keyboard. So, it’s a unique control code used in data communication or programming.
Control characters are essential in computer software and programming. However, in the extended table, some values might be different. Even though this table is old, it still works on some old devices. Remember, we’ve got more advanced character codes like Unicode or UTF-8 now. To sum up, text control codes help you handle data in lots of different ways.
How Does ASCII Work in a Binary System?
Every character in the character code table has a binary code. These codes allow computers to talk to each other. Basically, the binary codes stand for an electrical signal made up of 0s and 1s.
Let’s say you hit the big ‘A’ on your keyboard. The binary system gets involved. Your PC gives the letter ‘A’ the binary code 01000001. Then, the encoding system steps in. It looks at this binary code and tells you the matching value, which is 65, or ‘A’ according to its table.
So, it’s crucial to understand how ASCII works to turn text into code on electronic devices.
Applications of Character Encoding
- Computer Systems
It’s a big deal in computer systems to show all kinds of text. So, people use it a lot, especially in things like programming languages. It’s also handy in file systems and different software programs.
- Internet and Email
It’s super crucial for communication rules on the Internet. For example, it uses the SMTP protocol to send emails. Also, it shows text on the web, like with protocols such as FTP or HTTPS.
- Data Transmission
It helps send data between different computers. Like serial communication, it supports data sharing in network protocols.
- Printers and Screens
It shows text on printers and screens. Basically, it puts all the letters and symbols on a screen. It also helps print out text on devices like printers.
- Command Line Interfaces
It shows text in the command prompt you use in systems like Windows or Linux. So, when you type a command, it offers a letter or symbol.
- Legacy Systems and Devices
Its use is available in old systems, like calculators. So, when you type in a number, it displays just fine on the screen.
- Data Storage
It lets you save text data in formats like Word, PDF, and more. Also, it’s critical to understand the text in web stuff, like HTML.
To sum up, text encoding is part of everything involving information. So, when you type on your computer, know that this set is what makes it happen. When you hit a key, it quietly does its thing in the background, showing you the text.
ASCII and Unicode Comparison
Text encoding systems used in different jobs have some differences. One big difference is how many characters they can handle. For instance, one might handle less data, while another can take a lot more.
Especially, Unicode is excellent for tasks involving lots of languages. It’s newer than the other one and can handle special characters. But when it comes to speed, the old character set is faster than Unicode.
You can find a summary of the differences between ASCII and Unicode in the table below:
| Feature | ASCII | Unicode |
|---|---|---|
| Bit Size | 7 or 8 bits | 16 bit |
| Character Count | 128 or 256 characters | Over one million characters |
| Compatibility | Broad use, lots of compatibility | All world languages, multi-language support |
| Simplicity | Easy to get, simple setup | It is more complex and takes more learning |
| Speed | Faster processing and sending | Slower processing and sending |
| Supported Languages | Mostly English, limited | All world languages support many languages |
| Special Characters like Emojis | No | Yes, it includes emojis and symbols |
| Storage Requirement | It needs less storage space | It needs more storage space |
Using ASCII and the Problems It Has in Today’s Technology
ASCII, the basic tech in computing, is still important. But today’s global and mixed digital world brings some problems.
Sadly, the character set also has some limits. At first, ASCII gave a new way to share messages.
However, the simple design also had some limitations. In truth, it may not always match today’s needs.
1. Limited Character Set
One big limit of ASCII is its small set of characters. It also uses just a 7-bit code. But this way, it can only hold 128 characters.
The character set has simple English letters and numbers. Also, it has some marks and control codes.
However, this design is not suitable for letters in other languages. For example, it can’t show many special symbols well.
As the Internet grew into a worldwide space, user needs have changed, too. So, coding systems with bigger sets of characters are now used. For these reasons, ASCII is still small in today’s digital world.
For example, Chinese, Arabic, and Hindi have many more letters. These letters go far past the small limit of ASCII.
In fact, this problem creates big communication blocks for us. That’s why systems like Unicode began to appear. Unicode works with tens of thousands of letters.
Also, it works well with many languages and symbol sets. Now, we use the Unicode set much more.
2. Does Not Work Well with New Apps
ASCII is key for data rules in many programming languages. Because of its limits, we may face some problems with new apps. But we still make apps for users all over the world.
So, if we only use the ASCII set, we may have problems. For example, this happens when making text and sharing data. It can also hurt the user’s experience.
Also, many new apps now use systems like Unicode. In fact, this lets us match on many devices and platforms.
For example, if a web app uses only ASCII, we will have big problems. If it has letters outside this set, we can’t see the text correctly. This will cause errors, problems, or lost data.
In short, if we don’t keep up with new tech, users will be less happy. Also, our access to info will get worse.
3. Data Loss Potential
Moving data between ASCII and new codes is not always smooth. Often, there is a risk of data loss or damage.
We see this risk more in texts with non-ASCII letters. So, systems that are limited can’t handle these letters.
We see texts that look mixed up or hard to read. We find this problem more in user content. For example, comments, forums, or databases often have this. So, issues with letters when moving data cause significant errors.
4. Limited Support for Modern Features
Another problem with ASCII is that it has little help for new text. It does not support emojis and special symbols.
Today, emojis are very important in how we talk online. For example, we use them a lot in social media and chat apps.
But ASCII alone cannot hold these things. Also, emojis need extra codes to work. This lack is a big problem on many websites. So, it can hurt how we show feelings in messages.
How to Find ASCII Values by Entering Text with PowerShell
PowerShell helps you make commands and scripts on Windows computers. So, with a straightforward command, you can quickly figure out the ASCII code of a text you type. That’s why we’ve made a little script to help you turn text into numbers.
To see the ASCII values of text on Windows 11 or an older system, do these steps:
- To open PowerShell, type “PowerShell” in the Start menu and open it. You can also switch to it by typing it into the Command Prompt.
- Copy the PowerShell command from this link and paste it into the console. When you do this, you’ll get a message asking you to type in some text.
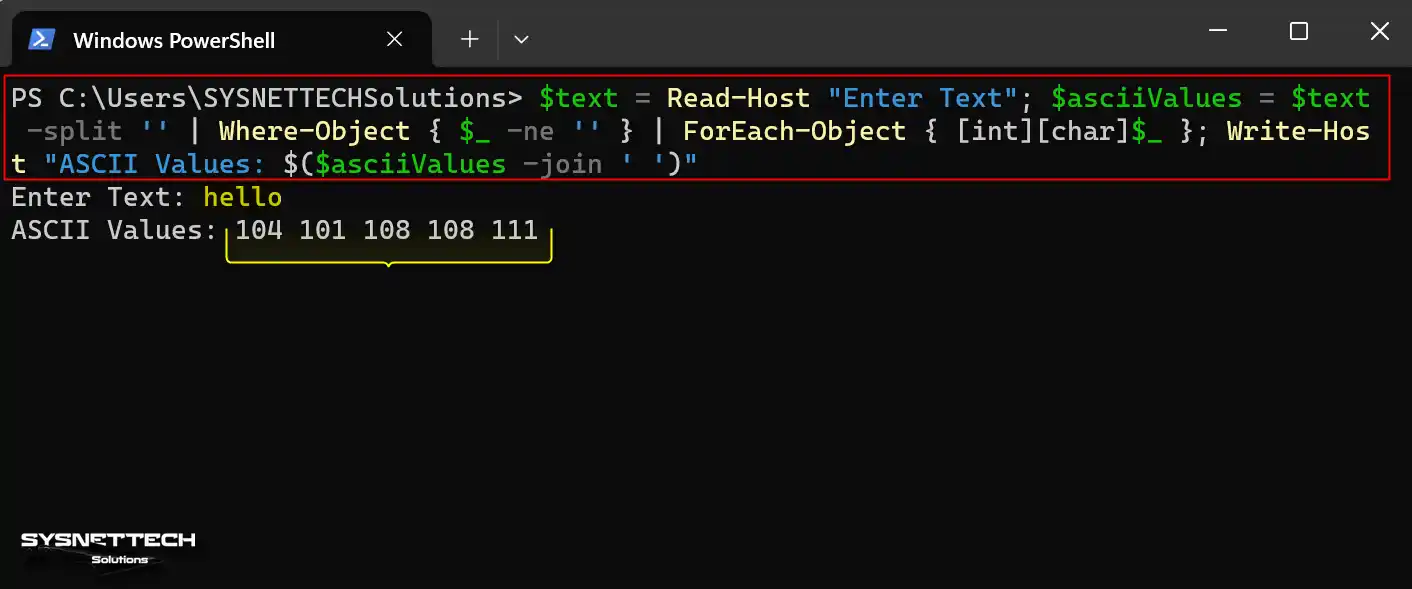
- For instance, type “hello” in the Enter Text part, all in small letters, and hit Enter.
- Now, in the console, under ASCII Values, you’ll see the codes for the word hello. This code is 104 101 108 108 111.
Frequently Asked Questions About ASCII (FAQ)
- What is ASCII in simple words?
- What is the ASCII format used for?
- Is ASCII a coding?
- Do all computers use this character encoding?
Conclusion
To sum up, the ASCII code has changed a lot since it started in the 1960s. It’s gone from Basic ASCII to Extended ASCII and Unicode, and even to newer ones like UTF-8. Programming is imperative because it helps devices talk to each other effectively. So, it’s crucial for making software and systems work well.
Even though there are new types of character codes coming up, the ASCII code is still essential. It’s used as a primary way to show text in lots of different areas. As technology keeps getting better, it’s interesting to see how this character set is changing. In short, it will keep influencing how computers work in the future.

Be the first to share your comment